

Блог
Фильтры в Яндексе
Фильтры группировки
Для того, чтобы разобраться, о чем идет речь, для начала необходимо понять, что из себя представляет ранжирование в Яндексе. Для этого можно обратиться к XML-поиску.
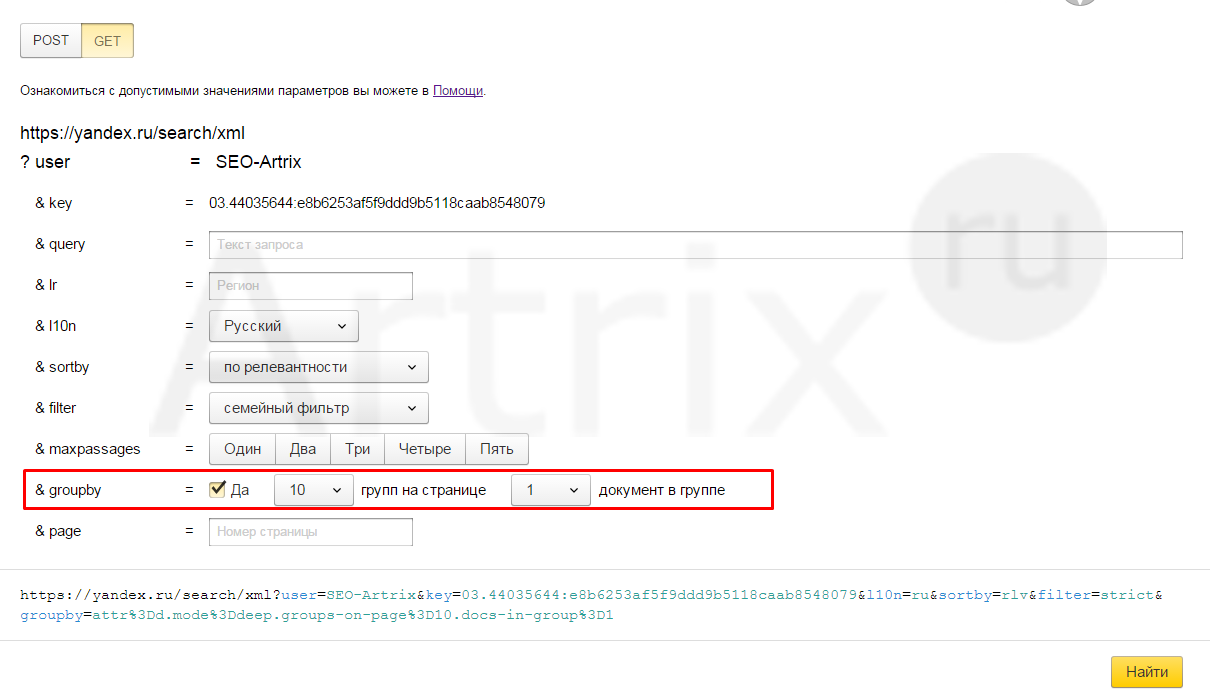
Параметр &groupby= в get-запросе XML с заданными на скриншоте настройками по сути и формирует ту выдачу, которую пользователи видят в обычном web поиске. Расшифруем, что задано в параметрах: мы включаем группировку результатов поиска с отображением 1 документа в группе. По сути это означает, что Яндекс ранжирует не страницы, а группы страниц, объединенные по домену, отображая среди них только 1 документ в поиске (за исключением витальных ответов и ряда некоторых других случаев).
К фильтрам группировки можно отнести фильтр аффилированности и фильтр за одинаковые сниппеты.
Фильтр аффилированности
Аффилирование между сайтами представляет собой объединение их 1 группу. И поэтому в результатах поиска отображается только 1 сайт (1 наиболее релевантный документ из всех документов группы). Фильтр накладывается в общем смысле за принадлежность нескольких сайтов одной компании.
Определение
- Поиск по контактной информации. Минусом является то, что аффилирование может происходить и при разных контактных данных и не быть столь очевидным.
- Можно воспользоваться сервисом http://tools.promosite.ru/old/clones.php однако, база достаточно сильно устарела (от 2010), поэтому часто уже не получится найти аффилированные сайты.
-
Можно сделать запрос вида [запрос << (lang:ru | site:sdfsdfsdf)]. Смысл здесь в том, что использование оператора site: в запросе отключает группировку. В конструкции выше мы лишь формально добавляем оператор site: в запрос для разгруппировки сайтов, но при этом у нас просто происходит поиск запроса по русскоязычным документам.
Пример: запрос [daily фургон], регион Санкт-Петербург. Результаты на 18.05.2015.
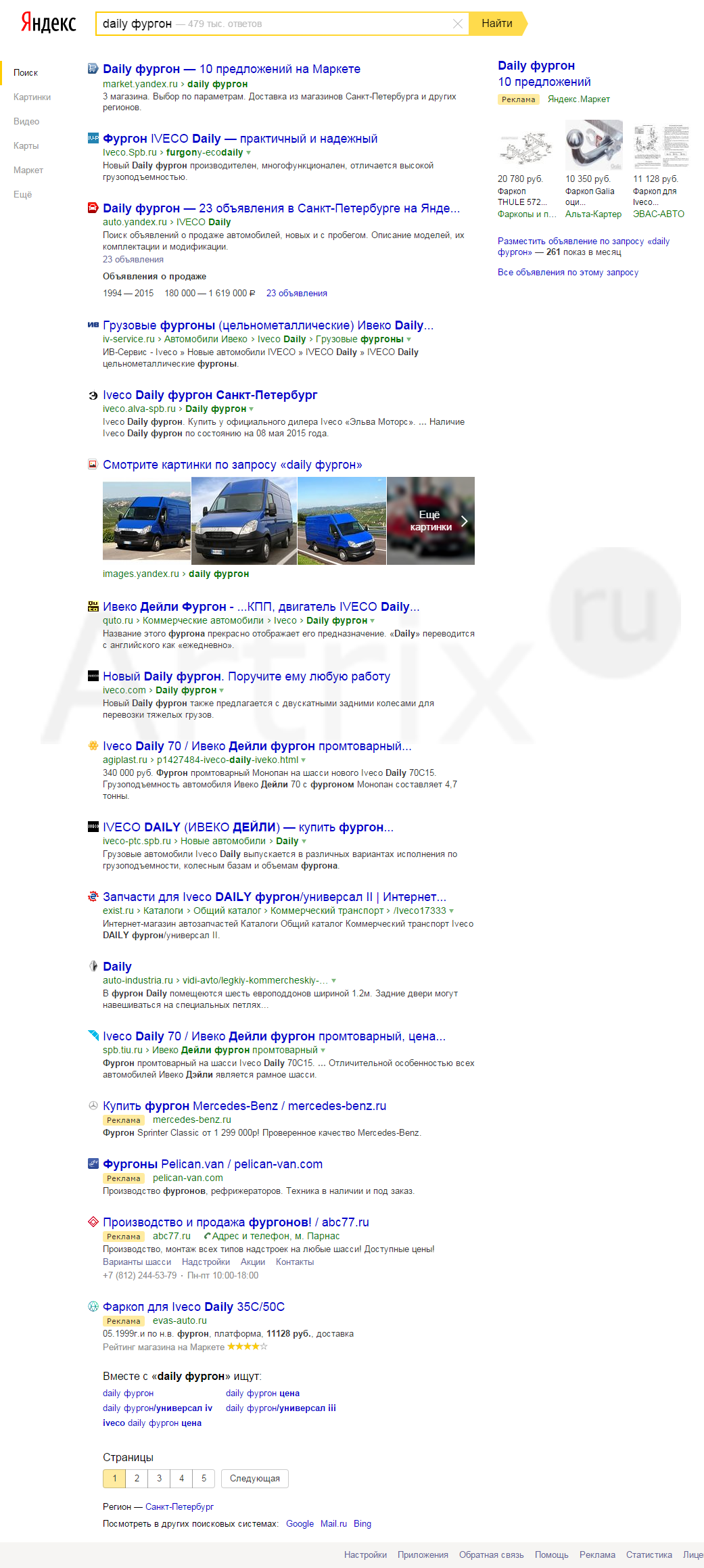
Как видно, при обычном запросе (без модификации) в выдаче не наблюдается сайт iveco-akt.ru, но он появляется при изменении запроса.
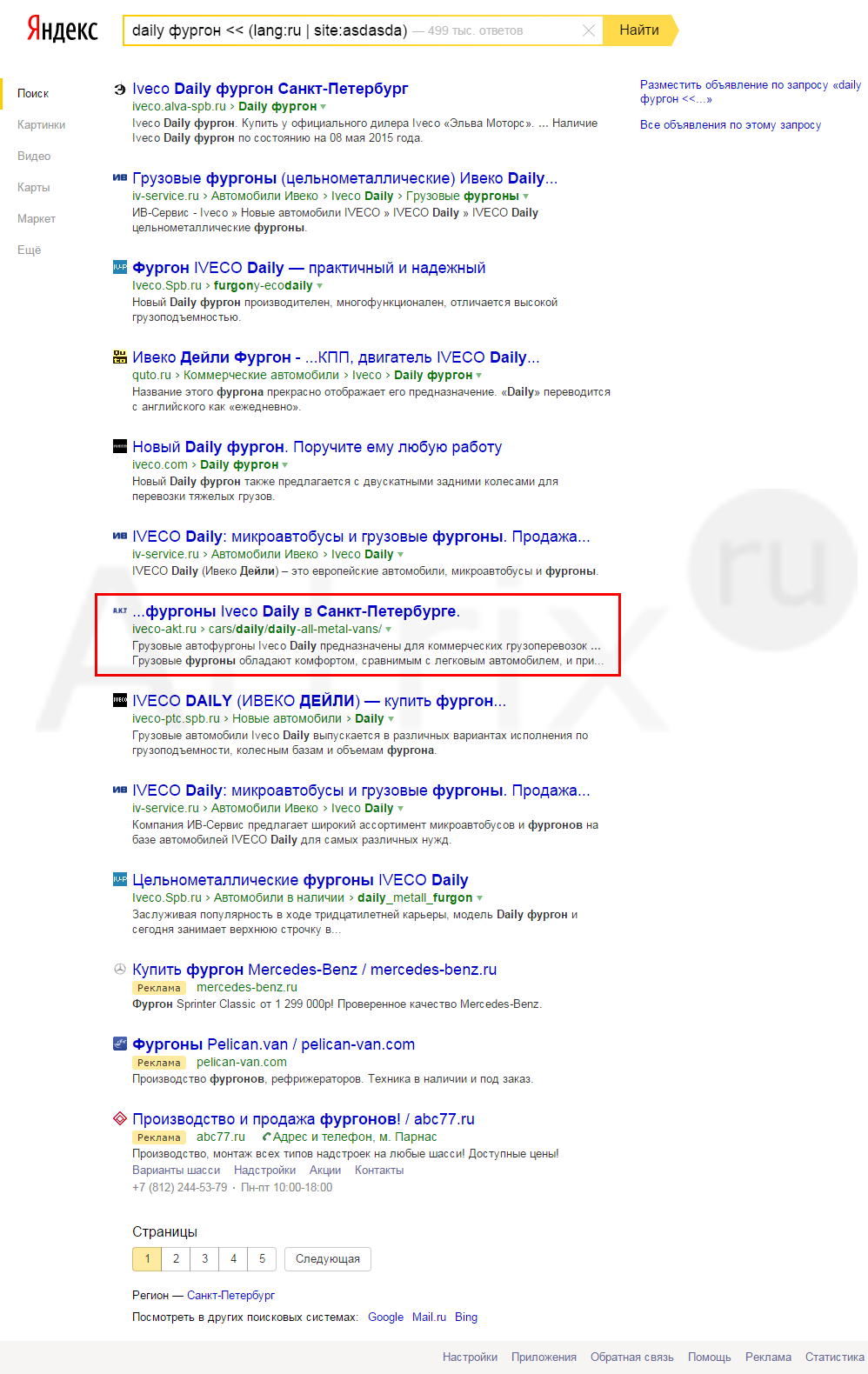
Осталось выяснить, с каким сайтом происходит группировка (наложение фильтра аффилированности). Для этого будем исключать сайты, стоящие выше сайта iveco-akt.ru, используя оператор исключения ~~ .
В общем виде конструкция запроса получается такая: [запрос ~~ site:site.ru].
При поиске сайта-аффилиата, получается, что таковым в данном случае является iv-service.ru, что видно из скриншота: при его исключении на 5 месте появляется сайт iveco-akt.ru.
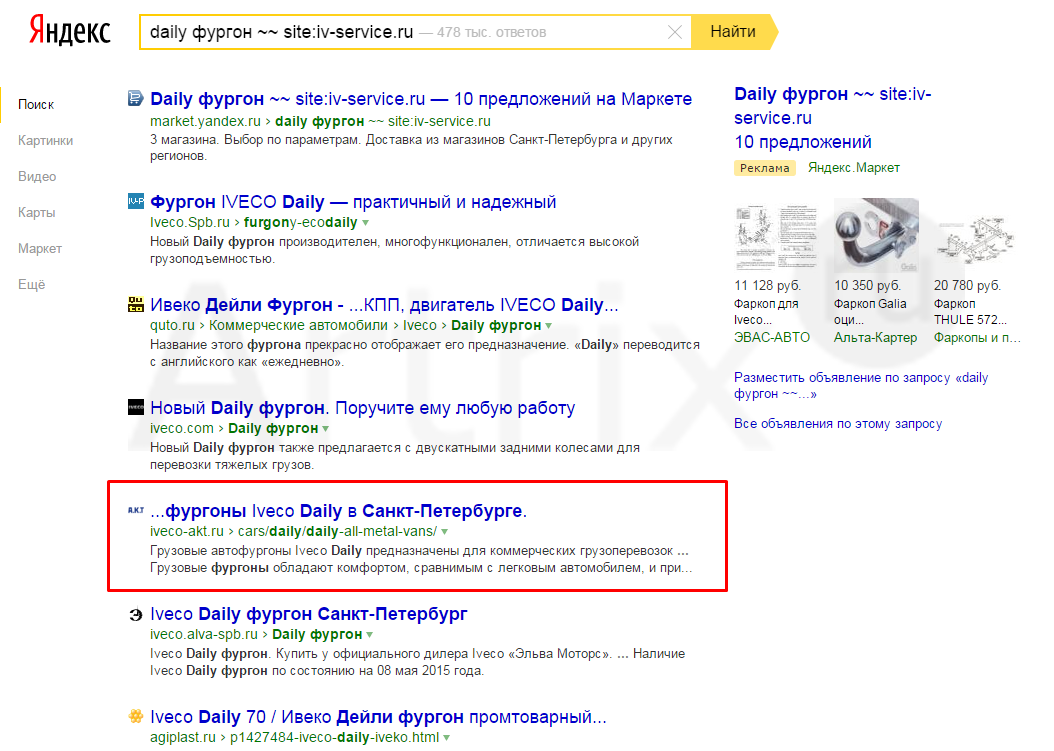
Минусом данного метода является то, что по ряду НЧ запросов, в которых присутствуют в выдаче многостраничные трастовые сайты, вся выдача будет заполонена документами таких сайтов. И увидеть присутствие искомого сайта, на который наложен фильтр, будет проблематично.
Фильтр за одинаковые сниппеты
В случае если документы по запросу имеют одинаковые сниппеты, они также объединяются в 1 группу. При этом аналогичным образом, как в случае с аффилированостью, сайт выпадает за первую сотню результатов поисковой выдачи.
Возьмем запрос [ES-9090 (4 в 1)], Санкт-Петербург, выдача на 18.05.2015.
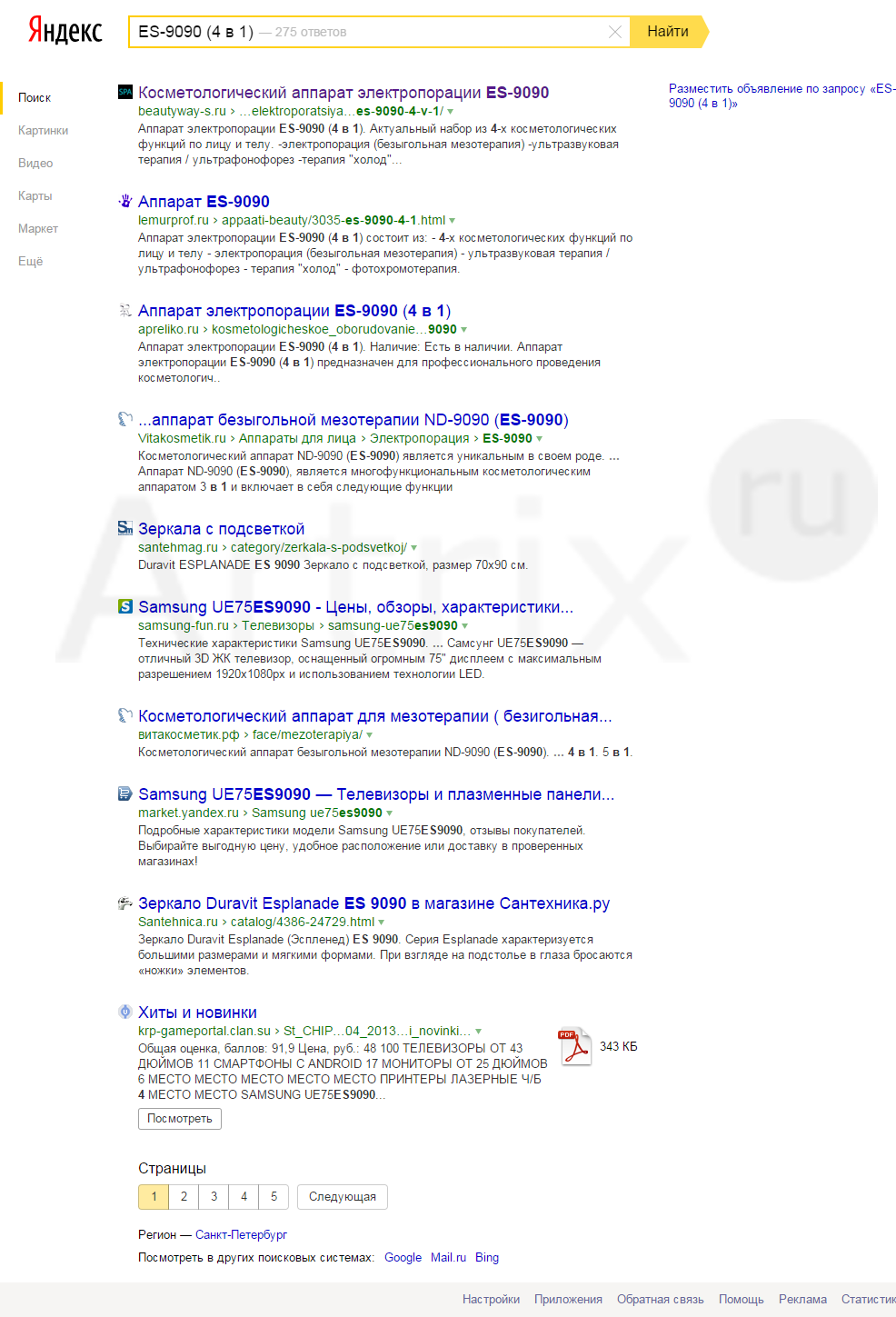
Теперь в адресной строке браузера добавим параметр &rd=0. Данный параметр отображает все результаты без исключения.
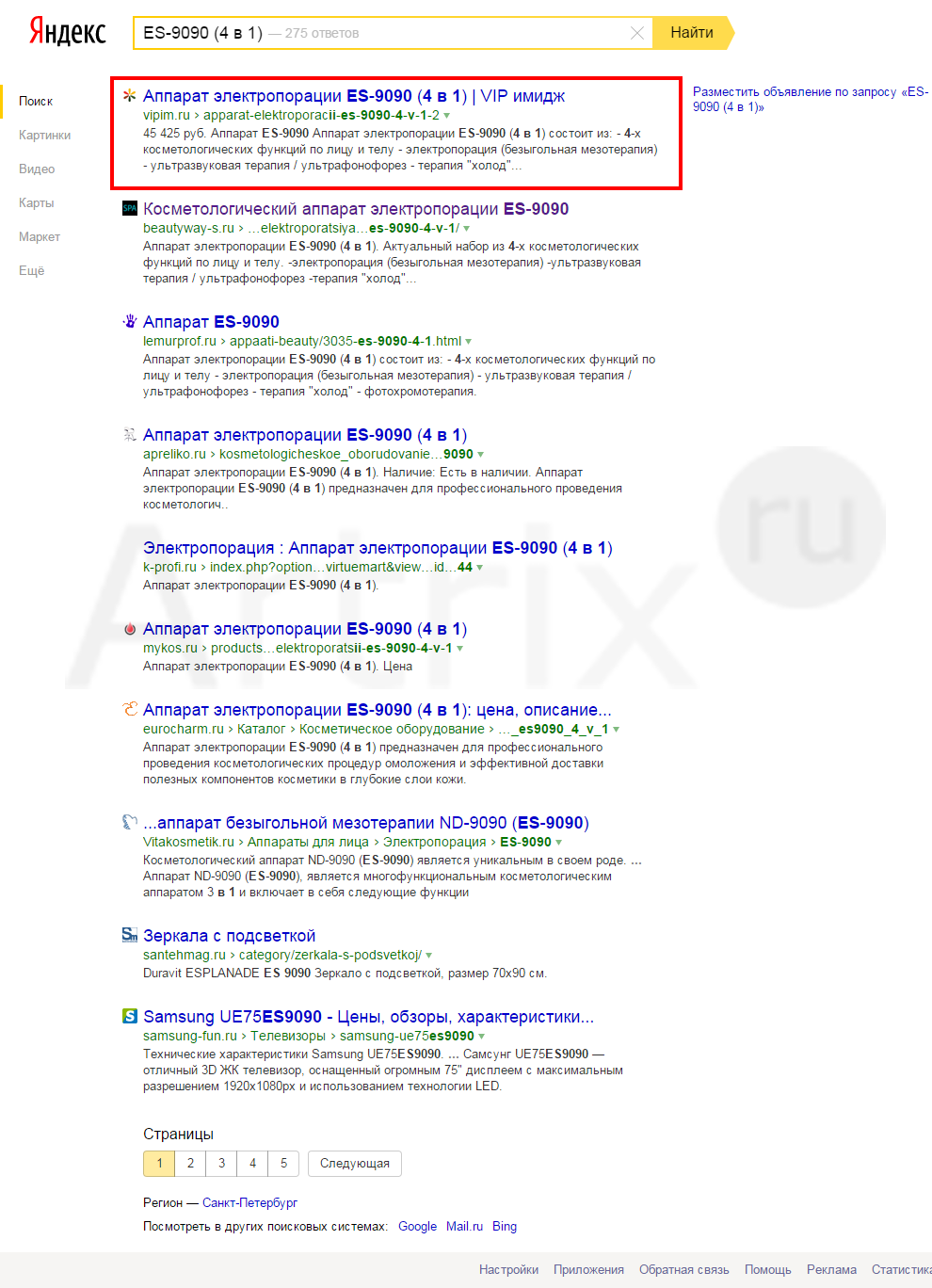
Как видно, при добавлении параметра &rd=0 появился сайт vipim.ru, у которого совпадает сниппет с сайтом beautyway-s.ru. Если при обычном поиске исключить последний, то на его месте появится vipim.ru. Для выхода из под фильтра нам нужно изменить сниппет. Либо переписав текст тех пассажей, который берет сниппетовщик для аннотации документа, либо закрыв часть текста в <noindex>, либо каким-либо другим способом.
Новый текстовый фильтр
Данный фильтр появился приблизительно летом 2014 года. Основными признаками попадания под данный фильтр является резкое проседание запроса или группы запросов, ведущих на страницу (до 100 позиций).
Для определения именно этого фильтра используется следующая методика: мы сравниваем наш сайт через оператор сравнения с другими сайтами, которые находятся в топ-10(20). В случае, если мы видим расхождения в ранжировании между обычной выдачей и суженной до нескольких доменов, можно говорить о наложении нового текстового фильтра.
В общем виде запрос будет выглядеть таким образом: [запрос (site:site1.ru | site2.ru | site3.ru |… |siteN.ru)].
Чтобы не проделывать данную операцию каждый раз руками, можно воспользоваться сервисом http://coolakov.ru/tools/new_filter/
Поделиться
Заполняя данную форму вы принимаете условия cоглашения об
использовании
сайта, в том числе в части обработки и использования персональных
данных, а так же политики конфиденциальности